

Como comentamos hace un par de semanas (las vacaciones me consumieron), para entender la inteligencia artificial debemos comprender primero lo que es un algoritmo.

Los robots con inteligencia artificial siguen un algoritmo para aprender, por eso muchas veces te encontrarás con el término “machine learning” que es el nombre de los distintos algoritmos que se usan para enseñar a una máquina a hacer algo.
Por lo general, dichos algoritmos de machine learning incluyen bases de datos gigantes sobre las que se le indica a la máquina qué es qué.
Cuando caminamos y vemos un árbol que nunca hemos visto, identificamos intuitivamente ciertas características similares a otros árboles como para poder decir que efectivamente eso que vemos es un árbol. Incluso no sabemos el nombre del árbol o cómo se distingue técnicamente un árbol de un cactus, pero razonablemente los diferenciamos.

Si queremos que un auto se maneje solo, debemos lograr que identifique un árbol. Para eso no basta con un par de imágenes o una descripción escrita. La máquina necesita procesar millones de imágenes que le permitan distinguir un árbol para no dirigirse hacia ellos.
Por detrás de estos algoritmos hay mucha matemática y estadística involucrada y diferentes tipos de aprendizajes posibles, distintos usos de la IA que influye en cómo es mejor que aprenda la máquina, etc. Aunque no me voy a meter ahí, es bueno que lo sepas por si te interesa aprender más.
En el mundo de herramientas y usos distintos de IA, las herramientas de “IA generativas” son las que están de moda. Éstas “generan” un resultado después de ingresarles algún tipo de consulta.
La que usé para la imagen final del post anterior, se llama “Chat GPT” y genera texto. Puedes ingresar desde “una lista para el supermercado con comida que alcance para alimentar 2 personas durante 2 semanas” o “qué decir cuando alguien tiene pesadillas”.
También existen herramientas que generan imágenes tras una consulta, como “Dall-E”, “Midjourney” o “Stable Difussion”.

Para generar esta imagen en Dall-E escribí en inglés: “imagen de una ciudad con ríos similar a Valdivia en Chile, con árboles en el fondo.” Si miras la imagen a la rápida crees que es Valdivia, pero si la ves de cerca verás que muchas cosas son manchas sin estructura definida.
Por mucho que sea realmente asombroso lo que pueden hacer en pocos segundos estas herramientas, hay dos consideraciones que me gustaría mencionarte para que distingas los desafíos a los que se enfrenta el desarrollo de las IA: los datos y los sesgos.
Napster, Torrents y Propiedad Intelectual
A principios de los 00’s era muy común la discordia de las industrias creativas (cine, música, videojuegos, editorial, etc.) con la industria tecnológica respecto a la piratería digital, fomentada por el anonimato y alcance global que demostraba el naciente internet.
En el año 2000 Napster, que era una aplicación que permitía compartir los archivos de música que tenías en tu computador con cualquier otro participante de la aplicación, era demandado por Metallica por 100 millones de dólares en daños por permitir que se compartiera sus canciones.
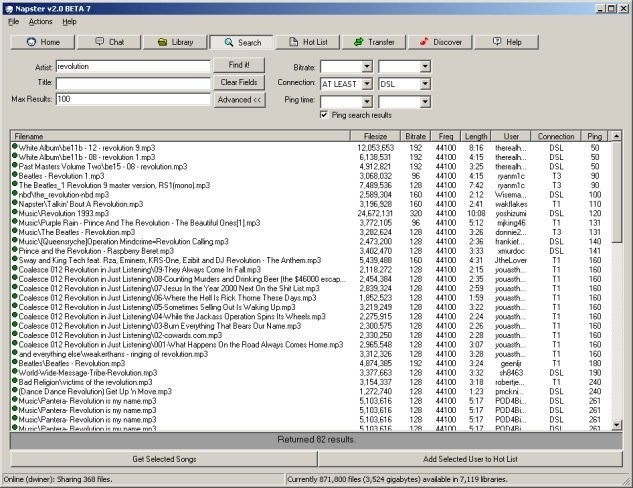
Luego de una serie de idas y vueltas en la corte, el 2002 Napster se declaró en bancarrota. Esto sentó un precedente importante para las compañías sobre el alcance de usar propiedad intelectual que no es tuya, independientemente que la provean los usuarios.1
Paralelo a lo que sucedió con Napster, muchas otras empresas permitían no sólo descargar música, sino todo tipo de archivos de los computadores de otros usuarios. A través del protocolo “BitTorrent”, se podían generar archivos que recopilaban la información de todos aquellos que tuvieran por ejemplo la película de Toy Story 3 y luego quien quisiera descargar dicha película, la descargaba de todos los otros computadores simultáneamente en pedazos que al terminar de descargarse se unían.
Se fundaron varias empresas que proveían de torrents a las personas, permitiéndoles buscar y luego descargar música, películas o lo que fuese (mientras existiera el torrent).
En este caso, la caída de la famosa página “The Pirate Bay” marcó el declive de este tipo de servicios.

En 2007 se decretó el cierre de la web, que también tiene su propia teleserie judicial con fundadores escapando a otros países para no enfrentar la justicia. El 2014 incluso la policía sueca requisó computadores y servidores de la empresa, dado que fieles a su consigna de “libertad a la información” tienen distintas formas de seguir “online” a pesar del cierre de sus operaciones. Si bien sigue existiendo hoy, muchas otras páginas de torrents en ese periodo enfrentaron a la justicia y fueron cerradas.
Paralelamente gran parte de los temas de propiedad intelectual se solucionaron con servicios como Netflix y Spotify (el primero en 2007 lanzó su servicio de streaming y el segundo en 2008). En ambos casos, los productores del contenido ganan dinero al estar en dichas plataformas.
¿Qué tiene que ver todo esto con la IA? Que justamente, las fuentes de datos que se han usado para entrenar a las IA detrás de “ChatGPT” o a “Dall-E”, son públicas, pero no exentas de copyright.
Sólo para que entiendas el alcance de lo que está pasando tras bambalinas:
Getty Images, una de las páginas más grandes de fotos con propiedad intelectual que debes pagar para usar, ingresó una demanda contra “Stability AI” por usar más de 12 millones de fotos con copyright para entrenar su generador de arte “Stable Diffusion”.2
La Oficina de Derechos de Autor de EE.UU declaró no registrables las imágenes o novelas gráficas generadas por “Midjourney”3
Microsoft anunció que integraría ChatGPT en su paupérrimo buscador Bing. Acto seguido se criticó a Google por no lanzar antes que Microsoft un buscador que tuviera integrado IA, siendo ellos número uno por lejos en ese servicio (nadie bingea, sólo googlean).
A los pocos días anunciaron “Bard” su servicio de buscador con IA integrado. En el lanzamiento, el chat cometió un error al responder equivocadamente un dato. Dicho error ocasionó una baja de 7% en la acción, equivalente a 100.000 millones de dólares. Casi 20% más que el presupuesto 2023 de Chile.
Sin embargo, dicho error fue un pie forzado porque en enero en su blog habían escrito que todavía quedaban varios desafíos en el desarollo de las IA.
Creo que en parte sabían que el copyright les iba a pegar y no tienen cómo frenarlo salvo que adrede limiten la información de la que se alimentan los robots o bien paguen una montaña de plata para acceder a ella.
Pero a este caso lo antecede otro dato que creo interesante.
El sesgo y el robot en sí
En junio Google suspendió a uno de sus ingenieros por ventilar que la IA sobre la que estaban trabajando, LaMDA, era según él un ser “sintiente”. Puedes revisar el diálogo de él con la IA aquí (está en inglés).4
Si consideramos que las personas que trabajan en una IA tienen valores, ideas y principios, es posible inferir que una IA (o cualquier software) tiene incorporado el mismo set de valores, ideas y principios. Lo mismo pasa con el tipo de información que le conectes a la IA para aprender, dicha información puede ser falsa o sesgada.
Particularmente en el mundo de la IA o de algoritmos más sofisticados que siguen aprendiendo, es muy importante la relación entre ambos sesgos.
Supón que quieres desarrollar un software para anticipar robos en un supermercado. Para esto podrías pensar que si tuvieras las imágenes de los robos que han ocurrido en los supermercado de una de las cadenas importantes, sería suficiente para generar una base de imágenes con la que el robot contrastaría rostros y avisaría ante la entrada de uno de estos sujetos al supermercado.

Si bien es un ejemplo, espero que hayas identificado los dos sesgos incorporados: las imágenes de robos anteriores podrían ser utilizadas para determinar comportamientos previos a un hurto, pero si contrastas sólo caras estás usando un sesgo de que “el que delinque, lo va a volver a hacer siempre” e incluso “todos los que se le parezcan, son delincuentes”.
No debemos olvidar que cuando googleamos algo, el algoritmo no intenta adivinar la respuesta (salvo que hagas sumas, pidas la hora o cosas concretas como esa), sino que confía que entre todo el conocimiento disponible en la Web existan páginas que contengan lo que estás buscando.
Cuando pensamos en herramientas de IA generativas, en vez de hacer una consulta y recibir una respuesta correcta, recibiremos una frase que tras analizar el patrón de nuestra consulta, hilará una respuesta que “probablemente” suene correcta. Es como que cada palabra de esta oración, la escribiera con una probabilidad según la palabra anterior.5
Una muletilla sería como tener por error una probabilidad alta de decir por ejemplo “emm” al final de cada frase. La IA puede incorporar las “muletillas” que existan en los datos sólo que no sabríamos identificar la muletilla.
¿Se puede hacer algo si no sé programar ni revisar códigos?
Obviamente 😁.
La revista de tecnología “Wired” escribió un artículo donde plantea los usos que le dará y los que no le dará a las IA generativas.
En resumen, la usarán para acelerar ciertos procesos de lluvia de ideas para títulos e ideas de artículos. En ambos casos entendiendo que muchas veces son poco disruptivas las ideas al ser una suerte de promedio de lo que hay en internet.
Sobre las imágenes incluyeron una frase interesante: “no usaremos imágenes generadas hasta que las empresas de IA compensen a los creadores sobre los que sus herramientas se apoyan para aprender”.
Es un lineamiento interesante, muy aterrizado y sujeto a cambios, según avance la industria de la IA.
Me parece importante estudiar esos casos, sacar ideas de cómo usar una IA podría ser provechoso para ti y cuándo es mejor dejarlas de lado por los problemas que pueden tener.
El primer texto era para entender a grandes rasgos, éste para revisar algunos riesgos. El próximo tratará sobre las oportunidades, usos e industrias que podrían verse positivamente afectadas.
¿Has notado sesgos en las apps que usas habitualmente?
Hoy uno de los temas pendientes que sigue sacando ronchas es la responsabilidad (o no) que tienen las RR.SS por lo que dicen los usuarios en ellas.
No creo que termine en lo mismo que Napster porque si la multa es muy grande, hay mucho inversionista dando vuelta tratando de entrar al mundo de las IA.
Muy importante, porque los derechos de una obra como un poema o un cómic duran 70 años después del fallecimiento de su autor, lo cual asegura poder rentabilizar el trabajo creativo.
Algunas respuestas me dejaron pensando que nos va a costar mucho saber si un robot piensa o sólo está programado para decir lo que dice.
Arvind Narayanan, un profesor de computación de la universidad de Princeton, les llama a las IA generativas “generadoras de caca”, por este principio de ser probabilísticas y no determinísticas en los casos que puedan.